[ 유데미 스터터스 4기 ] R 기초_11일차 TIL

오늘 무엇을 배웠나요?
✍️ R(데이터 타입, 자료구조, 변수, 함수, 패키지)
1. 데이터 처리과정과 R의 역할
2. 단축키
• Ctrl + S : 파일 저장
• Ctrl + O : 파일 불러오기
• Ctrl + Shift + N: 새 소스파일
• Ctrl + Shift + C: 코드 주석화
• Ctrl + 1~9: 화면이동 단축키
• Ctrl + Shift + Enter : 소스코드 실행
• Shift + Alt + K : 모든 단축키 확인
3. 데이터 타입
✅ 기본 데이터 타입
• 수치형 타입 (Numeric)
• 정수형 타입 (Interger)
✔ R에서 숫자는 기본적으로 Numeric. Integer로 지정하려면 값 뒤에 'L'기입
• 논리형 타입 (Logical)
• 문자형 타입 (Character)
• 복소수형 타입 (Complex)
# class() : 객체의 타입 확인
class(0) # "numeric"
class(1.1L) # "numeric", 1.1은 정수가 될 수 없음
class(TRUE) # "logical", 모두 대문자
class("1") # "character"
print(1/Inf) # "0"✅ 특별한 데이터 타입
• Inf (Infinity)
• NA (Not Available)
✔ 결측값을 나타내는 데이터 객체
✔ 실제로 값이 존재해야 하는 공간에 값이 없는 경우
• Null
✔ 실제로 값을 넣고 싶지 않을 때 '값이 없다'는 의미
✔ 변수를 선언만 하고 싶은 경우 Null값으로 초기화
• NaN (Not a Number)
✔ 수치값으로 표현할 수 없는 값을 나타내는 데이터 객체
4. 데이터 종류
✅ 데이터 차원에 따른 구분
- 1차원 : 단일 주제 데이터들을 모아 놓은 구조
- 2차원 : 복수 주제 데이터들을 모아 놓은 구조
- N차원 : N-1차원 데이터들을 모아 놓은 구조
✅ 데이터 구성에 따른 구분
- 단일형 : 한가지 타입의 데이터로만 구성된 데이터
- 다중형 : 여러가지 타입의 데이터로 구성된 데이터
✅ 데이터 값 연속성에 따른 구분
- 범주형 : 데이터 값이 이산적. 보통 논리값 또는 문자로 표현. 산술 연산 불가능
- 수치형 : 데이터 값이 연속적. 수치로 표현. 산술 연산 가능
5. R 자료구조
| 구분 | 1차원 | 2차원 | N차원 |
| 단일형 | 벡터 | 행렬 | 배열 |
| 다중형 | 리스트 | 데이터프레임 | - |
✅ 벡터(Vector)
- 1차원. 데이터 타입이 동일한 값들의 모음
- c(값)
- vector(“데이터 타입”, length = 벡터 크기)
c(1.7, "a") # "1.7" "a"
c(TRUE, 2) # 1 2
c("a", TRUE) # "a" "TRUE"📌 자동 형변환
- 데이터 타입이 다른 타입으로 변경되는 것
- 우선 순위 : Character > Numeric > Logical
✅ 행렬(Matrix)
- 단일형. 2차원 구조인 Vector의 집합
- matrix(nrow=행 크기, ncol= 열 크기)
- matrix(vector, nrow=행 크기, ncol= 열 크기)
- byrow = T : 데이터를 행부터 채움
✅ 배열(Array)
- dim 속성 크기가 2 이상인 자료구조
- array(vector, dim=vector)
✅ 리스트(List)
- 서로 다른 데이터 타입이 존재하는 값들의 모음
- list()
- 행은 list, 열은 vector 취급
- Vector, matrix, list등의 자료구조 포함 가능
✅ 데이터 프레임
- 다중형. 2차원 구조인 List의 집합
- data.frame(vector, vector, ...)
- 각 vector는 column값으로 삽입 됨
6. 내장함수
✅ 강제 형변환 함수
1) as 함수
- 데이터 우선순위 낮은 타입 -> 높은 타입으로 변화는 모두 가능
- 데이터 우선순위 높은 타입 -> 낮은 타입으로 변화는 일부 가능
✅ 데이터 생성 함수
1) seq 함수
- From 부터 by씩 증가하는 length개의 숫자로 이루어진 벡터 생성
seq( length=5, from=3, by=2) # c(3, 5, 7, 9, 11)2) rnorm 함수
- 평균이 mean, 분산이 se 인 정규분포를 따르는 n개의 숫자로 이루어진 벡터 생성
rnorm( n=4, mean =0, sd=1 ) # 평균 0, 분산 1인 정규분포 따르는 4개 데이터 생성3) runif 함수
- [min, max] 범위 사이 n개의 난수로 이루어진 벡터 생성
runif( n=4, min=1, max=100) # 최소값 1, 최대값 100 사이의 무작위 값 4개 생성7. 패키지(Package)
✅ 주요 패키지

✅ 패키지 관리 함수
install.packages("패키지 이름") # 설치
library() # 확인
library("패키지 이름") # 로딩
library(help= 패키지 이름) # 정보 출력
update.packages("패키지 이름") # 최신버전 업데이터
remove.packages("패키지 이름") # 삭제
# 패키지 이름::패키지 함수( ) -> library( ) 함수를 사용하지 않고, 특정 패키지의 특정 함수 사용
data(package = .packages(all.available = TRUE)) # 설치된 패키지의 모든 내장 데이터 보는 기능📍 실습
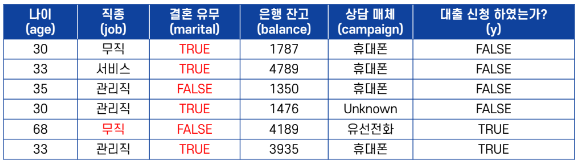
1. 문자 데이터 수정은 stringr 패키지의 함수 사용할 것
2. job 컬럼의 “은퇴” 값은 “무직”으로 대체 할 것
3. marital 컬럼은 logical 값으로 관리 할 것 (“결혼” 값은 T로, 나머지 값은 모두 F로 관리)
4. 수정된 결과물은 result_new 변수에 할당 후 출력 할 것
# stringr 패키지 설치 및 로딩
install.packages("stringr")
library("stringr")
# job 컬럼 수정
job_new <- str_replace(job, '은퇴', '무직')
# marital 컬럼 수정
marital_new <- str_replace(marital, '결혼', 'T')
marital_logical <- as.logical(marital_new) # marital_new 벡터 logical로 강제 형변환
marital_logical[is.na(marital_logical)] = FALSE # character -> logical로 형변환 시, "T", "F"외의 값은 NA로 변환 됨
print(marital_logical) # NA값을 F로 변환
result_new <- data.frame(age, job_new, marital_logical, balance, campaign, y)
print(result_new)
멘토링
1) 파이썬 vs R

2) 인덱싱과 슬라이싱
- 인덱스는 1부터 시작
- 슬라이싱은 끝인덱스 포함
- 마이너스 인덱스는 해당 인덱스 제외

3) 변수
- 변수 보기 : ls()
- 변수 삭제 : rm(변수명)
- 변수 모두 삭제 : rm(list=ls())
4) 주요 내장함수
✔ range() python과 혼동하지 않기

5) 실습
📍 벡터 만들기
✔ seq(시작, 종료, 간격)
✔ rep(숫자, 반복횟수)
# 1부터 10까지의 숫자로 이루어진 벡터 만들기
c(1,2,3,4,5,6,7,8,9,10)
c(1:10)
seq(1,10)
# 1,2,3,50,51,52,53,54,55로 이루어진 벡터 만들기
c(1:3, 50:55)
# 1부터 100까지 3 간격의 숫자로 이루어진 벡터 만들기
seq(1,100,3)
# 0.1부터 1까지 0.1 간격의 숫자로 이루어진 벡터 만들기
seq(0.1,1,0.1) # range함수와 다르게 소수 사용 가능
# 1,1,1,1,1 숫자로 이루어진 벡터 만들기
rep(1, 5)
# 1,2,3을 5번 반복하는 벡터 만들기
rep(1:3, 5)
rep(c(1,2,3), 5)📍 벡터 인덱싱/슬라이싱
absent <- c(3,2,0,4,1)
# 인덱싱
absent[1]
absent[-3] # 해당 인덱스 제외
# 슬라이싱
absent[1:3]
absent[-c(4,5)]
# 불린 인덱싱
# 1,3,5번째 요소만 인덱싱
absent[c(TRUE,FALSE,TRUE,FALSE,TRUE)]
# 팬시 인덱싱
absent[c(1,3,5)] # 판다스에는 리스트. R은 벡터로 묶어 인덱싱할 요소 전달
# 벡터 absent 각 요소에 이름 붙이기
names(absent) <- c('Mon','Tue','Wed','Thr','Fri')
# 이름으로 요소 접근하기
absent['Mon']
absent[c('Mon', 'Wed')]앞으로 개선해야 할 점, 추가로 배워야 할 점이 무엇인가요?
오늘부터 R 이러닝을 시작했다! R은 판다스와 달리 vector를 많이 사용하는데 개념에 익숙하지 않아서 헷갈린다. 멘토링 시간에 인덱싱과 슬라이싱을 추가로 배워 실습을 했는데 아주 조금 응용이 들어갔다고 잘 모르겠더라..! ㅎㅎ 멘토링 시간을 통해 이틀간 남은 R수업을 위해서라도 R 문법에 얼른 익숙해져야겠다고 생각했고 또 R,Python,SQL의 비슷한 문법을 잘 구분해야겠다고 생각했다. 😂
TODO
1) 11일차 강의 CLEAR
2) 11일차 TIL CLEAR
3) 알고리즘 CLEAR