[ 유데미 스터터스 4기 ] 파이썬 데이터 시각화_6일차 TIL

오늘 무엇을 배웠나요?
✍️ 데이터 시각화 (그래프 스타일링 / Seaborn / 기온변화 분석 )
그래프 스타일링
1. 그래프 강조하기 (수직선과 수평선)
✅ 수평선
- plt.axhline(y좌표, x축시작위치, x축끝위치)
▷ 수평선의 길이가 1 - plt.hlines(y, x축시작좌표, x축끝좌표)
✅ 수직선
- plt.axvline(x좌표, y축시작위치, y축끝위치)
- plt.vlines(x, y축시작좌표, y축끝좌표)
2. 그래프에 설명적기
✅ 텍스트
- plt.text(x좌표, y좌표, 텍스트)
- rotation = 회전각도
- ha : horizontal alignment / va : vertical alignment
- bbox = {'boxstyle' : 'round'/'square', 'fc' : facecolor, 'ec' : edgecolor,...}
✅ 텍스트와 화살표
- plt.annotate('텍스트', xy=(화살표x, 화살표y), xytext=(텍스트x, 텍스트y), arrowprops={화살표속성})
- arrowprops={'width' : , 'headwidth' : , 'headlength' : , 'shrink' : ,...}
3. 2중 y축 표시하기
- fig, ax = plt.subplots() ▷ 축을 분리하기 위해 객체지향 사용
- axes객체.twinx() ▷ 2중 y축 만들기. x축을 공유하는 새로운 axes객체 생성
- axes객체.set_xlabel(x레이블) ▷ 축 레이블 표시하기
- axes객체.set_ylabel(y레이블)
- axes객체.set_ylim(y축눈금범위) ▷ y축 범위 지정
- axes객체.set_yticks(y축눈금) ▷ y축 눈금 / 가지고 있는 값만 표현
- axes객체.legend() ▷ 범례 표시. axes객체별로 호출
- axes객체.grid()
fig, ax1 = plt.subplots() # 두가지 정보를 하나의 그래프에 그리기
ax1.bar(age, height, color='skyblue', width=0.5, ec='lightgray', label='height')
ax2 = ax1.twinx() # 2중 y축 만들기
ax2.plot(age, weight, color='darkred', marker='o', ls='-.', label='weight')
ax1.set_xlabel('나이') # 축 레이블
ax1.set_ylabel('키(cm)')
ax2.set_ylabel('몸무게(kg)')
ax1.set_ylim(150,180) y축 범위
ax2.set_ylim(60,90)
ax1.set_yticks(height) # y축 눈금
ax2.set_yticks(weight)
ax1.tick_params(axis='y', colors='skyblue')
ax2.tick_params(axis='y', colors='darkred')
ax1.legend() # 범례
ax2.legend()
ax1.grid(axis='y', ls='--', color='skyblue') # 그리드
ax2.grid(axis='y', ls='--', color='pink')
plt.show()
Seaborn을 활용한 여러가지 그래프
- sns.barplot(data=데이터프레임명, x=x축컬럼, y=y축컬럼)
- sns.scatterplot(data=데이터프레임, x=x축컬럼, y=y축컬럼)
- sns.lineplot(data=데이터프레임, x=x축컬럼, y=y축컬럼)
- sns.countplot(data=데이터프레임, x=컬럼)
- sns.rugplot(data=데이터프레임, x=컬럼)
- sns.displot(data=데이터프레임, x=컬럼)
- sns.boxplot(data=데이터프레임, x=x축컬럼, y=y축컬럼)
- sns.violinplot(data=데이터프레임, x=x축컬럼, y=y축컬럼)
- sns.stripplot(data=데이터프레임, x=x축컬럼, y=y축컬럼)
- sns.swarmplot(data=데이터프레임, x=x축컬럼, y=y축컬럼)
- x축 데이터로 그룹핑한 y축 데이터의 평균값을 계산하여 그래프를 그려준다.
- 신뢰구간(CI:Confidence Interval)을 함께 표시
- estimator = 통계함수
- hue = y를 그룹핑할 컬럼 ( 색상 변경 : palette = {구분:색상} )
기온변화 분석 및 시각화
📍 서울시 연간 평균기온 변화
# 서울시 서브셋 생성
df_seoul = df[df['지점명']=='서울']
# 연간 평균기온 추출
df_seoul_mean = df_seoul.groupby(df_seoul['일시'].dt.year)['평균기온(°C)'].mean()
# 이상치 제거
df_seoul_mean.drop(index=[1950, 1953], inplace=True)
# 시각화
plt.plot(df_seoul_mean, 'g.-')
plt.title('서울시 연 평균기온의 변화', size=15)
plt.show()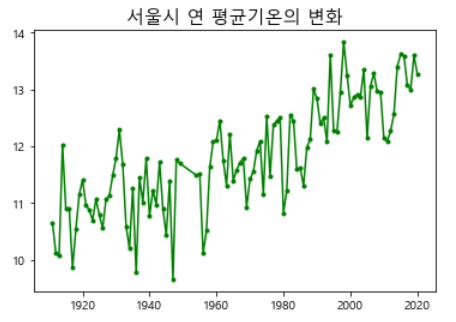
📍 서울시 연간 평균, 최저, 최고 기온 변동 폭 비교
# 세 개의 플롯을 하나의 axes에 그리기
plt.figure(figsize=(15,7))
plt.plot(df_seoul_mean, 'g.-', label='평균기온')
plt.plot(df_seoul_min, 'b.-', label='최저기온')
plt.plot(df_seoul_max, 'r.-', label='최고기온')
plt.legend(loc=(0,1.01), ncol=3, fontsize=12, edgecolor='k')
plt.title('서울시 기온 변화', size=20, pad=30)
plt.xticks(range(1910,2021,5))
plt.yticks(range(-25,42,5))
plt.grid(ls=':')
# 수평선 ( 각 플롯의 최대, 최소값의 위치에 수평선 그리기 )
plt.axhline(df_seoul_mean.min(), color='gray', ls='--')
plt.axhline(df_seoul_mean.max(), color='gray', ls='--')
plt.axhline(df_seoul_min.min(), color='gray', ls='--')
plt.axhline(df_seoul_min.max(), color='gray', ls='--')
plt.axhline(df_seoul_max.min(), color='gray', ls='--')
plt.axhline(df_seoul_max.max(), color='gray', ls='--')
plt.show()
📍 전국 지점별 연평균 기온 변화
# 2020년 기온 데이터 추출
df_2020 = df[df['일시'].dt.year==2020]
# 2020년 지점별 연 평균기온 추출
df_2020_mean = df_2020.groupby('지점명')['평균기온(°C)'].mean().sort_values(ascending=False)
# 시각화
plt.figure(figsize=(20,5))
plt.bar(df_2020_mean.index, df_2020_mean.values, color='lightgreen')
plt.xticks(rotation=90)
# 최고, 평균, 최저 라인 표시
plt.axhline(df_2020_mean.max(), color='r', ls='--', label='최고:'+str(round(df_2020_mean.max(),1)))
plt.axhline(df_2020_mean.min(), color='b', ls='--', label='최저:'+str(round(df_2020_mean.min(),1)))
plt.axhline(df_2020_mean.mean(), color='g', ls='--', label='평균:'+str(round(df_2020_mean.mean(),1)))
plt.legend(loc=(0,1.01), ncol=3, fontsize=12, edgecolor='k')
# 서울지역 표시
plt.bar('서울', df_2020_mean.loc['서울'], color='g')
plt.text('서울', df_2020_mean.loc['서울']+0.5, '서울('+str(round(df_2020_mean.loc['서울'],1))+')'
, ha='center', fontsize=15)
plt.title('2020년 전국 지점별 연 평균기온', size=20, pad=30)
plt.show()
📍 지점별 기온 분포 비교
# 서귀포, 서울, 대관령 서브셋
df_2020_sgp = df_2020[df_2020['지점명']=='서귀포']
df_2020_seoul = df_2020[df_2020['지점명']=='서울']
df_2020_dgr = df_2020[df_2020['지점명']=='대관령']
# 시각화
# 스타일 파라미터
plt.rcParams['hatch.color'] = 'w'
# 서브플롯 만들기(plt.subplots())
fig, ax = plt.subplots(1,3, figsize=(15,5), sharex=True, sharey=True)
# 서귀포 일평균기온 히스토그램
ax[0].hist(df_2020_sgp['평균기온(°C)'], rwidth=0.9, hatch='//')
ax[0].set_title('2020년 서귀포 일 평균기온 분포')
ax[0].set_xlabel('일 평균기온(°C)')
ax[0].set_ylabel('일수')
# 서울 일평균기온 히스토그램
ax[1].hist(df_2020_seoul['평균기온(°C)'], rwidth=0.9, hatch='--')
ax[1].set_title('2020년 서울 일 평균기온 분포')
ax[1].set_xlabel('일 평균기온(°C)')
# 대관령
ax[2].hist(df_2020_dgr['평균기온(°C)'], rwidth=0.9, hatch='xx')
ax[2].set_title('2020년 대관령 일 평균기온 분포')
ax[2].set_xlabel('일 평균기온(°C)')
# 0°C 수직선 표시
ax[0].axvline(0, color='k', ls='--')
ax[1].axvline(0, color='k', ls='--')
ax[2].axvline(0, color='k', ls='--')
plt.tight_layout()
plt.show()
👉 서귀포는 영하와 30도가 넘었던 날씨가 없었음. 20도 초반에 가장 많은 분포를 보임.
👉 서울은 영하 10도까지 떨어진 날씨가 있었음. 20도 중반에 가장 많은 분포를 보임.
👉 대관령은 비교적 영하권이 데이터가 많이 분포함. 0도 부근에서 가장 많은 분포를 보임.
조별 토의 학습
강의를 들으면서 따로 실습을 하다가 궁금한 점이 있어서 질문을 했다.
그래프에 화살표와 텍스트를 추가했는데 왼쪽 사진처럼 결과가 나와서 화살표 방향은 최적으로 자동 지정되는 것인지 궁금했다. 그런데 조원분이 텍스트의 위치를 조정해보라고 하셔서 오른쪽처럼 결과를 만들 수 있었다.
xy=(화살표x,화살표y)는 화살표가 가리키는점, xytext=(텍스트x,텍스트y)는 텍스트의 왼쪽아래점의 위치를 지정하는 것이고 화살표 끝점 = 텍스트 왼쪽아래점이라고 정리했다.


멘토링
1) seaborn이 훨씬 간단한데 matplotlib을 사용해야 하는 상황은?
👉 seaborn은 matplotlib을 기반으로 하고 matplotlib 메서드를 사용하기 때문에 둘 다 이해가 필요함. 또한 seaborn은 데이터를 자유롭게 넣기보다는 전처리가 필요함.
2) 데이터 분석 후 결과에 대한 추가적 인사이트를 찾는 팁?
👉 인사이트를 찾는 것은 해당 분야에 대한 도메인 지식이 관건. 데이터 수집, 전처리, 시각화, 모델링은 기술적인 부분이며 기획(목적, 문제, 가설), 인사이트 도출, 적용은 도메인 지식이 필요함.
3) rugplot이 의미하는 바, 언제 주로 사용하는지, 어떻게 해석해야 하는지?
👉 x축의 데이터의 위치를 표시해 주는 것. 데이터가 많지 않을 때 사용함.
4) 서브플롯을 만드는 다양한 방식이 있는데 어떻게 사용해야 하는지?
👉 특징이 다 다르기 때문에 모든 방식을 알아두는게 좋음. pyplot의 서브플롯 기능이 가장 간단하지만 커스터마이징을 해야할 때는 객체를 만들어서 그려야하는 경우가 있음.
앞으로 개선해야 할 점, 추가로 배워야 할 점이 무엇인가요?
matplotlib랑 seaborn의 차이점을 잘 몰랐는데 오늘 확실히 알게되었다. seaborn으로 그래프를 그려도 스타일링은 matplotlib의 함수를 사용하니까 오히려 불편하다고 생각했는데 두 방식을 비교하며 실습하다보니 seaborn이 확실히 더 편했다!
오늘 tips, titanic, iris 데이터셋으로 배운 내용으로 따로 실습을 해봤는데 쉽지 않았다.. 데이터 타입과 분포를 먼저 정확히 숙지하고 그 특징을 잘 드러내줄 그래프 타입을 선정해야하는 점을 또 몸소 깨달을 수 있었다. 하나의 그래프에 여러 컬럼을 나타내는 경우에서 x축을 공유하고 있기 때문에 특히 어려웠고 의도한대로 잘 그릴 수 없었다.. 그래서 이 부분을 더 신경써야겠다. 👊
TODO
1) 6일차 강의 CLEAR
2) 6일차 TIL CLEAR
3) 활용 그래프 실습 CLEAR