
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 로우코드
- 브라이틱스스튜디오
- 노코드
- 대학생대외활동
- BrighticsStudio
- 태블로
- 데이터사이언스
- Brightics
- 유데미큐레이션
- 데이터시각화
- 노코드AI오픈소스
- 취업부트캠프
- Brightics_Studio
- 브라이틱스
- 데이콘
- 데이터드리븐
- 유데미부트캠프
- Brightics서포터즈3기
- 코딩없이
- 브라이틱스서포터즈3기
- 데이터사이언티스트
- 대학생서포터즈
- 부트캠프후기
- Brightics studio
- 유데미코리아
- 서포터즈
- 스타터스부트캠프
- 데이터분석
- 유데미
- 삼성SDS
- Today
- Total
지수
[ 유데미 스타터스 ] 33일차 TIL 프로젝트 기반 Tableau 실전 트레이닝 - SuperStore 대시보드, LOD(INCLUDE, EXCLUDE, FIXED) 예제 본문
[ 유데미 스타터스 ] 33일차 TIL 프로젝트 기반 Tableau 실전 트레이닝 - SuperStore 대시보드, LOD(INCLUDE, EXCLUDE, FIXED) 예제
하지수지수 2023. 3. 24. 10:00
1. 태블로 실습
- LOD는 RAW 데이터를 꼭 확인해야 함
➡ 값이 나외기만 하면 됐다고 생각하지만 필터의 영향을 받음
➡ 3~4개 데이터 랜덤으로 뽑아서 확인해 보기, 카운트해보기, 인덱스 삽입해서 필터링 되는 게 있는지 확인해 보기
1.1 INCLUDE 간단 예제
1) 데이터의 깊이가 상대적으로 깊어야 함
2) 집계를 2번 해야할 때 (평균의 최대값, 최소값)
3) 설정한 차원의 영향을 INCLUDE한 차원을 기준으로 결과 출력
▶ 예시 1


- 왼쪽은 시/도의 평균 매출, 오른쪽은 시/도안에 있는 도시의 평균 매출 MIN MAX
- INCLUDE에 고정시키고 싶은 차원은 도시(CITY)
- Bay of Plenty는 평균적으로 잘 하고 있는 것 같지만 빈부격차가 많은 시/도라고 이해할 수 있음
▶ 예시 2

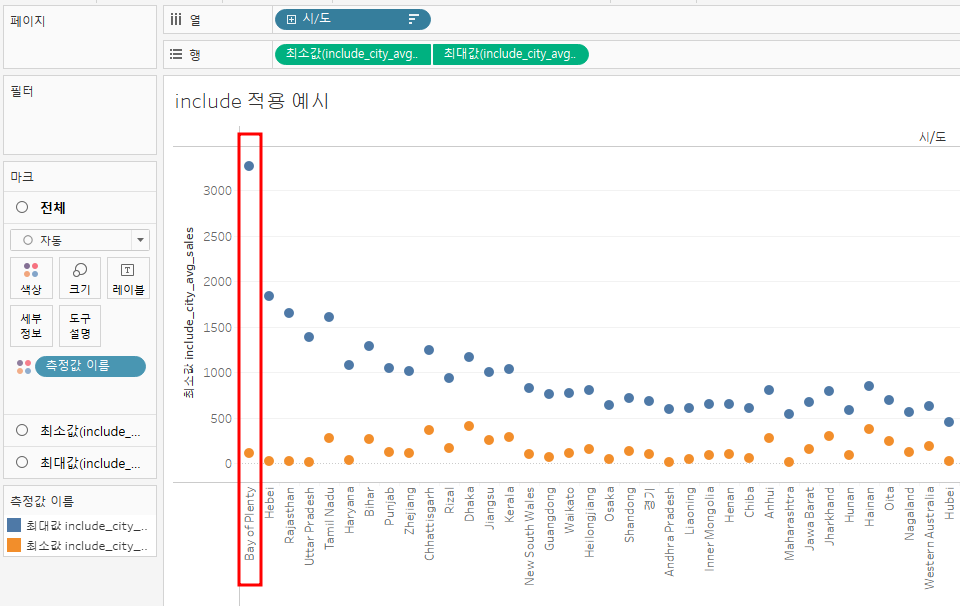
- 왼쪽은 시/도 평균 매출의 MIN MAX, 오른쪽은 시/도안에 있는 도시의 평균 매출 MIN MAX
- 왼쪽은 개인으로 보는 것 (백만장자와 노숙자를 비교하는 것) -> 인사이트를 하나도 얻을 수 없는 그래프
- 오른쪽은 하나의 카테고리의 평균을 보는 것 (EX. 상위 25% 수익을 가진 사람)
💡 평균이나 MIN MAX가 의미 있는 값으로 전달될 수 있도록 도와주기 위해 INCLUDE를 사용 (둘 다 무조건 정답이 아니라 말이되는 것인지 고려해야 함)
💡 FIXED는 시/도 무슨 상관이야. 나는 도시로 고정을 했는데. (서울 A도시 광주 A도시 -> A의 평균을 보여줌) 그러나 INCLUDE는 INCLUDE한 차원이 있어도 VLOD에 다른 차원을 넣으면 고려함
[TIP] 구구절절 LOD를 설명해야 하면 안쓰는게 맞음
1.2 EXCLUDE 간단 예제
1) 특성으로 설정됨
2) EXCLUDE LOD에 명시된 차원을 제외한 후 집계가 이루어지고 VLOD에 맞추어 표현하기 위해 첫번째 단계 결과를 복제함
3) 효과적으로 EXCLUDE를 쓰기 위해서는 EXCLUDE LOD안에서 선언된 차원이 반드시 VLOD에 들어가 있어야 함
4) LOD 식은 항상 RAW LEVEL 값으로 집계를 꼭 씌어주어야 함. ATTR, AVG, SUM상관 없음
EX) ATTR{EXCLUDE : } 셋 다 결과 똑같은데 ATTR 권장
▶ 예시 1
# EXCLUDE_PROFIT_%
SUM([Profit]) / ATTR({EXCLUDE [City] : SUM([Profit])})- CITY의 PROFIT 합계 / CITY를 포함하고 있는 전체 STATE/PROVINCE의 PROFIT 합계
- ATTR 지우면 오류남. 하지만 집계는 의미가 없음

- 끌어오는 100%(STATE/PROVINCE)가 이미 VLOD에 있기 때문에 COUNTRY/REGION을 제거해도 결과가 똑같음

▶ 예시 2
- SALES-봉투를 기준(차원이 달리지면 안됨. 현재 차원은 하위 범주)으로 SALES-봉투보다 매출이 잘 나왔는지 아닌지

① SALES-봉투만 표시
IF [하위 범주] = '봉투' THEN [매출]
ELSE NULL
END
② EXCLUDE
{EXCLUDE [하위 범주]: SUM([SALES-봉투])}** EXCLUDE가 제외한 차원이 VLOD에 있어야 효율적으로 사용할 수 있음
** 하위 범주를 없애기 때문에 앞에 있는 범주의 값을 복사
③ 차이
- SALES-봉투를 기준으로 매출이 적게 나왔는지 아닌지 확인
- 집계값으로 틀만 변형시켜 주기 위해 ATTR 사용
SUM(매출)-ATTR([Exclude-봉투])
💡 INCLUDE, EXCLUDE는 자유도가 너무 떨어져서 FIXED를 씀. 그러나 FIXED가 VLOD에 있는 차원을 고려하지 않기 때문에 발생하는 문제 때문에 INCLUDE, EXCLUDE를 사용함
💡 LOD는 유연해서 많이 응용할 수 있음. 그러나 RAW 데이터를 꼭 확인하고, 정제되고 깨끗한 테이블에서만 사용 권장
1.3 FIXED 이론 & 간단 예제
: 내가 원하는 특정 차원으로 화면을 고정시키는 것
1) 화면 VLOD를 고려하지 않고 내가 선언한 그 차원으로 집계하는 것
2) 유연함
3) 결과의 종류는 INCLUDE, EXCLUDE는 측정값만 결과로 나오는데 DIMENSION 필터의 영향을 받음. 필터가 들어가면 계산 결과가 바뀌게 됨
4) FIXED는 차원도 나옴. 특히 날짜, 최근 한 달 등
5) 작동 순서에서 FIXED는 상위에 위치하고 제어하는 개념으로는 CONTEXT FILTERS가 있음
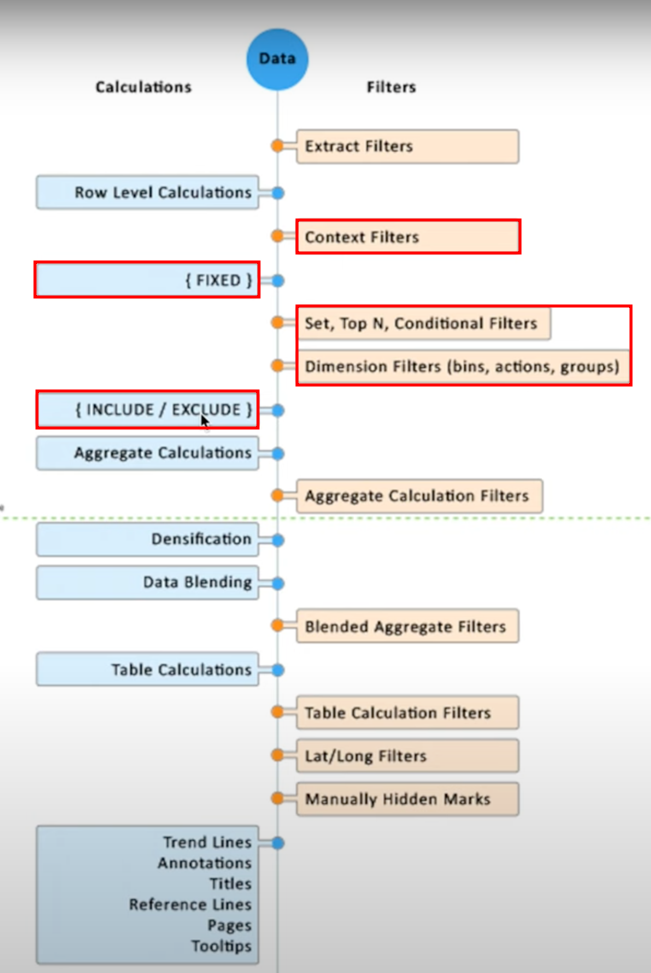
▶ FIXED에 고정시킨 차원이 VLOD에 있는 경우, 없는 경우
# sales avg by sub - fixed
{FIXED [하위 범주] : AVG([매출])}
▶▶ 예시 1 (FIXED에 고정시킨 차원이 VLOD에 있는 경우)
- 기능적으로 어떻게 작동 되는가. INCLUDE, EXCLUDE와 똑같음
- 하위 범주를 기준으로 범주는 INCLUDE, 제조업체는 EXCLUDE 결과를 보여줌


▶▶ 예시 2 (FIXED에 고정시킨 차원이 VLOD에 없는 경우)
- 하위 범주를 고정시키지만 VLOD에 설정할 차원은 시/도와 도시
- EX) 경기도 광주의 매출 평균, 하위 범주가 고정된 매출 평균 (광주 - 백단에서 보관함, 사무용품, 악세서리의 평균을 구함)

1.4 집합 (FIXED + 필터) 예제
▶ 예시 (FIXED에 고정시킨 차원이 VLOD에 없는 경우)
- 주문 ID가 기준. 시/도에서 0이 넘는(T/F) 주문 ID의 매출 합계 %
# profitable
{FIXED [주문 Id]: SUM([수익])>0}- 합계(매출) -> 테이블 계산 -> 구성 비율 -> 옆으로
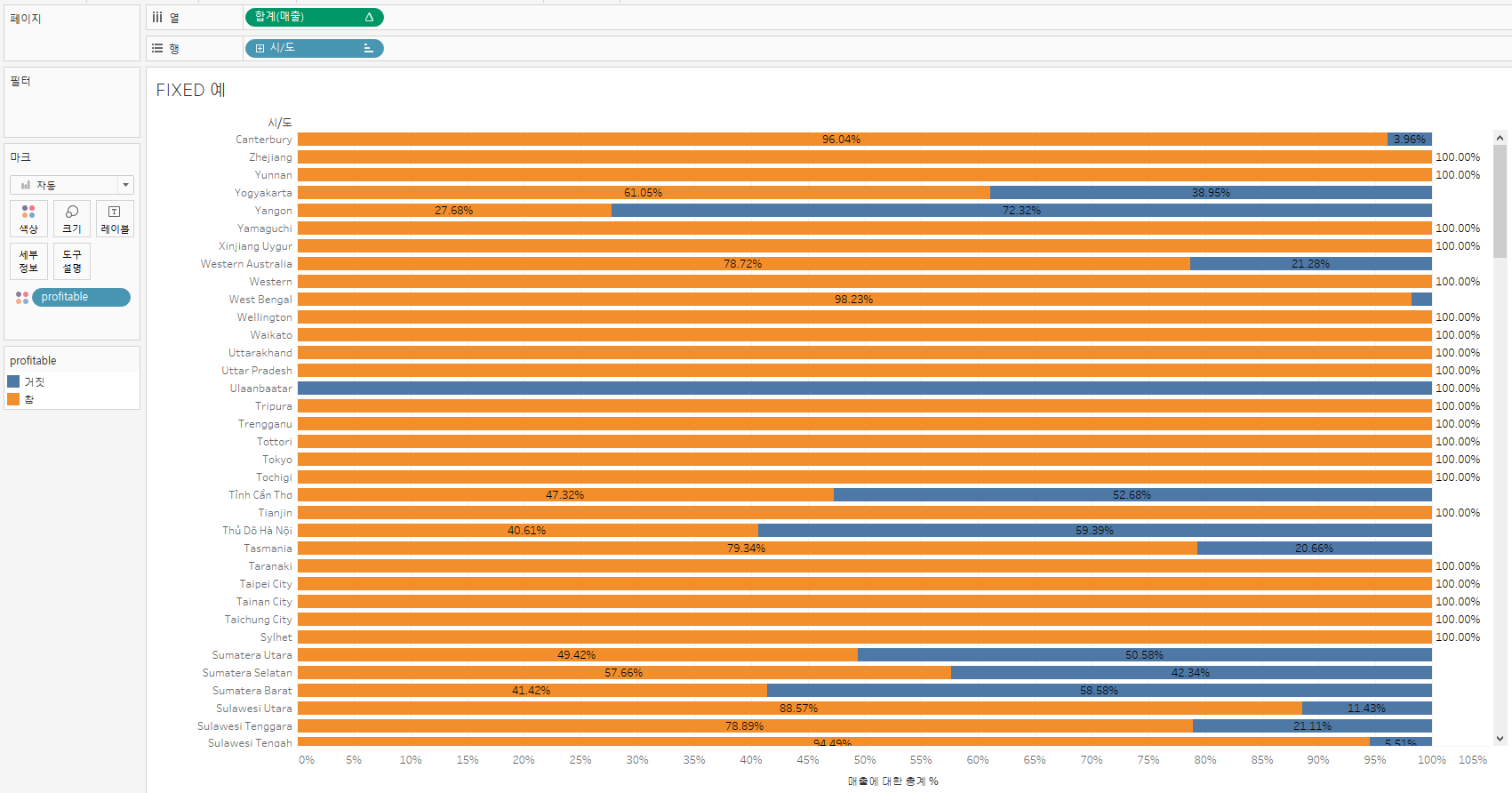
1.5 차이점
✔ FIXED
1) 결과가 측정값 또는 차원으로 나옴
2) 뷰에 있는 차원과 상관 없음
✔ INCLUDE / EXCLUDE
1) 항상 측정값으로 나옴
2) 뷰에 있는 차원에 영향을 받음
3) INCLUDE : VLOD에서 포함하지 않고 있을 때 어떤 특정 차원을 끌어들여서 함께 고려하고 싶을 떄
4) EXCLUDE : VLOD에 특정 차원이 들어가 있는데 그 차원을 제외하고 계산하고 싶을 때
▶ FIXED가 있는데 INCLUDE를 왜 쓸까?
- 결과가 다를 수 있음
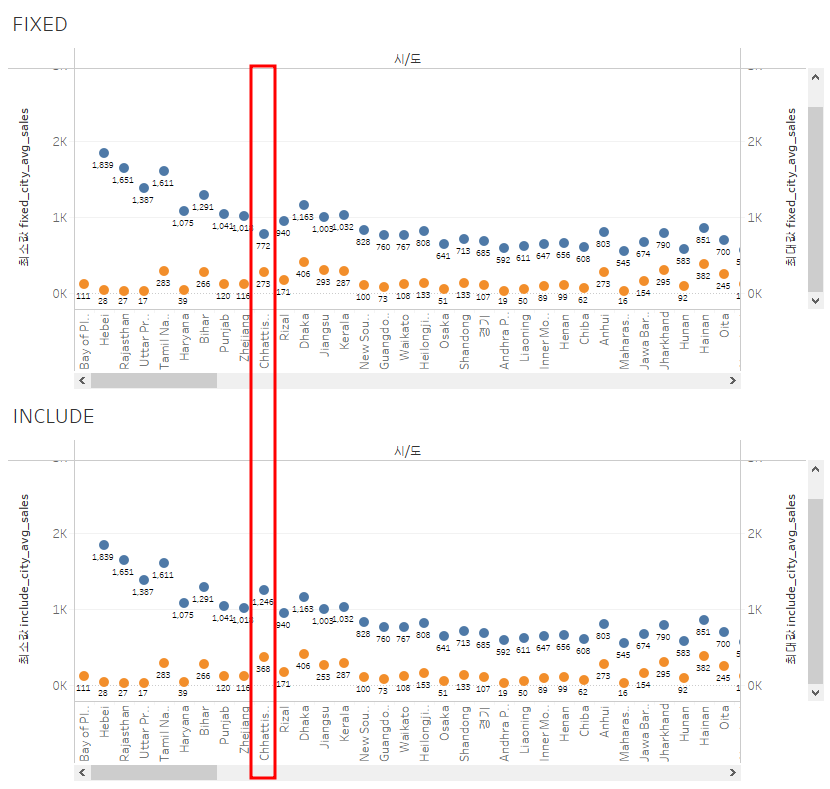
- 데이터 원본을 확인해야 함
- 데이터 원본 필터 편집 -> 추가 -> 도시/Kota or SQL

- Chhattisgarh의 Kota라는 도시가 2개의 시/도에 존재
- FIXED는 도시로 고정하여 시/도 상관 없이 하나의 도시로 판단하였고, INCLUDE는 시/도에 따라 도시를 다르게 판단함
- INCLUDE가 말이 되기 때문에 INCLUDE를 사용함


2. 팀 별 과제
💁 나는 회사의 상품 세일즈 트래킹 팀에서 일하고 있습니다. LOD와 그동안 배운 방법을 사용하여 다양한 뷰 포인트로 어느 sub-category or category or product가 잘 하고 있는지, 어디서 어떻게 집중해야 하는지 알고 싶습니다.
📢 오늘의 과제
- 대시보드 2개 만들고 대시보드 1개에 대해서만 파워포인트 슬라이드 한 장으로 대시보드가 무엇을 나타내려 했는지 목표 및 설명
- 대시보드 2개를 만들고 1개에 대해서만 PPT 슬라이드 한 장으로 대시보드가 무엇을 나타내려 했는지 설명
- 대시보드 1 : Include or Exclude + 매개변수 넣어서 조정이 가능한 형태로 만들기
- 대시보드 2 : Fixed를 이용해서 자유롭게 구성
- 예시
1) 우리가 판매에 집중해야 하는 주 및 도시는?
2) 카테고리 중 매출은 가장 좋지만 주/도시에 따라 하위 범주의 판매 차이가 많이 나는 곳은? 그렇다면 해당 카테고리는 어느 주에서 판매해야 할까?
3) 판매 주력 상품은 x인데 지금 어떤 카테고리의 상품이 잘 나가고 있을까? 아니면 발 빼야 하는 상품은?
4) 어떤 경우 전체의 평균으로 보는 것이 데이터의 분별력을 떨어뜨립니다. 하나의 필드를 고정시키고 VLOD에서 비포함되어 있는 그래프를 만들었을 때 내가 왜 그 필드를 고정시켜서 분별력을 높이려 했나요?
5) 세그먼트별로 서브 카테고리가 다른 퍼포먼스를 보이나요?
2.1 브레인스토밍
1) 데이터 세분화하여 살펴보기
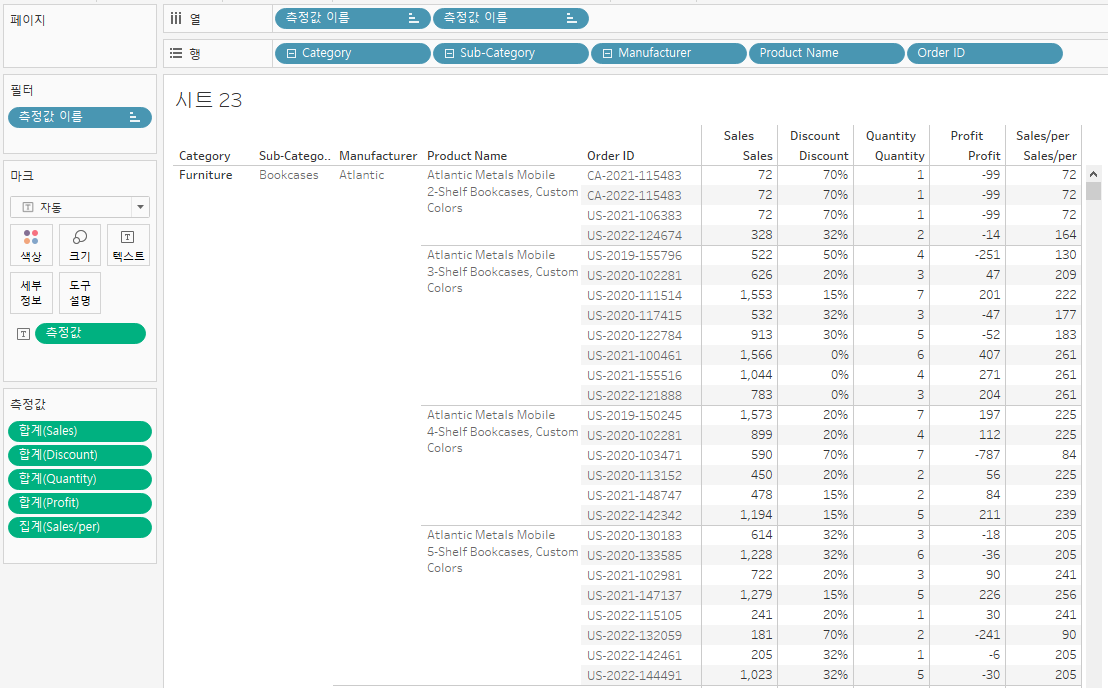
2) 주제 아이디어
- 목표 : 매출과 비용을 고려하면서 수익성을 높이는 방법 (효율성을 높이는 방법)
▶ 이익이 음수(-)인 프로덕트가 있고, 이들은 대체로 할인율이 높은 것을 발견
▷ 적정 할인율(이익이 음수X)을 지정해주면 어떨까?
▶ 선택과 집중
▷ 수익이 높은 지역에 집중하는건 어떨까?
▷ 수익이 높은 상품에 집중하는건 어떨까?
▷ 날짜(계절, 공휴일, 블랙프라이데이)에 집중하는건 어떨까?
▶ 어느 상품이 중요하고 이익이 되는가
▷ 가격이 높은 상품을 많이 파는 것 VS 재구매율이 높은 상품을 많이 파는 것
▶ 현황 파악
▷ 지역 별 세부 카테고리의 매출/수익 현황을 파악하는건 어떨까?
▷ 환불한 고객, 물건의 현황을 파악하는건 어떨까?
회고
오늘부터 시작되는 팀 과제는 자유롭게 주제를 정해야 하다보니 정말 많은 의견이 나왔다. 지역/제조업체/날짜 등 무엇을 기준으로 성과를 보여줄지, 잘 하고 있는 상품 혹은 뺄 상품 중 무엇을 선정할 것인지, 데이터셋에서 사용할 세부 기간과 카테고리는 무엇으로 할 것인지 등등 결정해야 하는 부분이 많아서 혼란스러웠다. 또 이렇게 다양하게 나온 아이디어를 모두 사용하고 싶다는 의욕이 더해져 아직 정확한 주제를 정하지는 못했다. 그래서 일단은 할인율/지역/환불/시계열 이렇게 파트를 줄이고 나눠서 내일 분석 결과를 확인해보기로 했다!! 내일도 화이팅 😜